Java 语法
发布时间:2020-08-31编辑:caoww阅读(924)
2. Java 语法
2.1. 字符型常量和字符串常量的区别?
形式上: 字符常量是单引号引起的一个字符; 字符串常量是双引号引起的若干个字符
含义上: 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)
占内存大小 字符常量只占 2 个字节; 字符串常量占若干个字节 (注意: char 在 Java 中占两个字节)
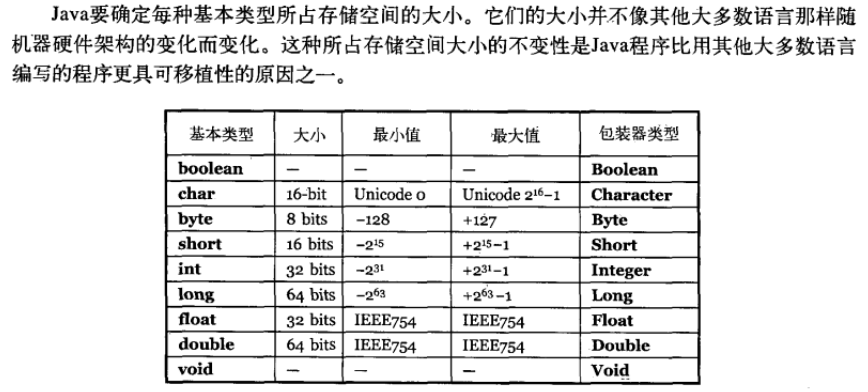
java 编程思想第四版:2.2.2 节
2.2. 关于注释?
Java 中的注释有三种:
单行注释
多行注释
文档注释。
在我们编写代码的时候,如果代码量比较少,我们自己或者团队其他成员还可以很轻易地看懂代码,但是当项目结构一旦复杂起来,我们就需要用到注释了。注释并不会执行,是我们程序员写给自己看的,注释是你的代码说明书,能够帮助看代码的人快速地理清代码之间的逻辑关系。因此,在写程序的时候随手加上注释是一个非常好的习惯。
《Clean Code》这本书明确指出:
代码的注释不是越详细越好。实际上好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。
若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。
举个例子:
去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可
// check to see if the employee is eligible for full benefitsif ((employee.flags & HOURLY_FLAG) && (employee.age > 65))应替换为
if (employee.isEligibleForFullBenefits())
2.3. 标识符和关键字的区别是什么?
在我们编写程序的时候,需要大量地为程序、类、变量、方法等取名字,于是就有了标识符,简单来说,标识符就是一个名字。但是有一些标识符,Java 语言已经赋予了其特殊的含义,只能用于特定的地方,这种特殊的标识符就是关键字。因此,关键字是被赋予特殊含义的标识符。比如,在我们的日常生活中 ,“警察局”这个名字已经被赋予了特殊的含义,所以如果你开一家店,店的名字不能叫“警察局”,“警察局”就是我们日常生活中的关键字。
2.4. Java中有哪些常见的关键字?
| 访问控制 | private | protected | public | ||||
|---|---|---|---|---|---|---|---|
| 类,方法和变量修饰符 | abstract | class | extends | final | implements | interface | native |
| new | static | strictfp | synchronized | transient | volatile | ||
| 程序控制 | break | continue | return | do | while | if | else |
| for | instanceof | switch | case | default | |||
| 错误处理 | try | catch | throw | throws | finally | ||
| 包相关 | import | package | |||||
| 基本类型 | boolean | byte | char | double | float | int | long |
| short | null | true | false | ||||
| 变量引用 | super | this | void | ||||
| 保留字 | goto | const |
2.5. 自增自减运算符
在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1,Java 提供了一种特殊的运算符,用于这种表达式,叫做自增运算符(++)和自减运算符(--)。
++和--运算符可以放在操作数之前,也可以放在操作数之后,当运算符放在操作数之前时,先自增/减,再赋值;当运算符放在操作数之后时,先赋值,再自增/减。例如,当“b=++a”时,先自增(自己增加 1),再赋值(赋值给 b);当“b=a++”时,先赋值(赋值给 b),再自增(自己增加 1)。也就是,++a 输出的是 a+1 的值,a++输出的是 a 值。用一句口诀就是:“符号在前就先加/减,符号在后就后加/减”。
2.6. continue、break、和return的区别是什么?
在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词:
continue :指跳出当前的这一次循环,继续下一次循环。
break :指跳出整个循环体,继续执行循环下面的语句。
return 用于跳出所在方法,结束该方法的运行。return 一般有两种用法:
return;:直接使用 return 结束方法执行,用于没有返回值函数的方法return value;:return 一个特定值,用于有返回值函数的方法
2.7. Java泛型了解么?什么是类型擦除?介绍一下常用的通配符?
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,这也就是通常所说类型擦除 。 更多关于类型擦除的问题,可以查看这篇文章:《Java泛型类型擦除以及类型擦除带来的问题》 。
List<Integer> list = new ArrayList<>();list.add(12);//这里直接添加会报错list.add("a");Class<? extends List> clazz = list.getClass();Method add = clazz.getDeclaredMethod("add", Object.class);//但是通过反射添加,是可以的add.invoke(list, "kl");System.out.println(list)泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型//在实例化泛型类时,必须指定T的具体类型public class Generic<T>{ private T key; public Generic(T key) { this.key = key; } public T getKey(){ return key; }}如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);2.泛型接口 :
public interface Generator<T> { public T method();}实现泛型接口,不指定类型:
class GeneratorImpl<T> implements Generator<T>{ @Override public T method() { return null; }}实现泛型接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{ @Override public String method() { return "hello"; }}3.泛型方法 :
public static < E > void printArray( E[] inputArray ) { for ( E element : inputArray ){ System.out.printf( "%s ", element ); } System.out.println(); }使用:
// 创建不同类型数组: Integer, Double 和 CharacterInteger[] intArray = { 1, 2, 3 };String[] stringArray = { "Hello", "World" };printArray( intArray ); printArray( stringArray );常用的通配符为: T,E,K,V,?
? 表示不确定的 java 类型
T (type) 表示具体的一个java类型
K V (key value) 分别代表java键值中的Key Value
E (element) 代表Element
更多关于Java 泛型中的通配符可以查看这篇文章:《聊一聊-JAVA 泛型中的通配符 T,E,K,V,?》
2.8. ==和equals的区别
== : 它的作用是判断两个对象的地址是不是相等。即判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
equals() : 它的作用也是判断两个对象是否相等,它不能用于比较基本数据类型的变量。equals()方法存在于Object类中,而Object类是所有类的直接或间接父类。
Object类equals()方法:
public boolean equals(Object obj) { return (this == obj);}equals() 方法存在两种使用情况:
情况 1:类没有覆盖
equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。使用的默认是Object类equals()方法。情况 2:类覆盖了
equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
举个例子:
public class test1 { public static void main(String[] args) { String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 if (aa == bb) // true System.out.println("aa==bb"); if (a == b) // false,非同一对象 System.out.println("a==b"); if (a.equals(b)) // true System.out.println("aEQb"); if (42 == 42.0) { // true System.out.println("true"); } }}说明:
String中的equals方法是被重写过的,因为Object的equals方法是比较的对象的内存地址,而String的equals方法比较的是对象的值。当创建
String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
String类equals()方法:
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false;}2.9. hashCode()与 equals()
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
1)hashCode()介绍:
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
public native int hashCode();散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
2)为什么要有 hashCode?
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode?
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
3)为什么重写 equals 时必须重写 hashCode 方法?
如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖。
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
4)为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode。
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
标签:
